Инструменты для распознавания речи с открытым исходным кодом

В статье от SVDS рассматриваются основные инструментарии для распознавания речи, использующие традиционные, основанные на n-граммах, модели и скрытые марковские модели (HMM).
Будучи частью R&D команды по глубокому обучению SVDS, мы заинтересованы в сравнении рекуррентной нейронной сети (RNN) с другими подходами к распознаванию речи. Еще несколько лет назад передовой подход к распознаванию речи был основан на фонетическом принципе, включающем в себя отдельные компоненты для произношения, акустики и языковых моделей. Как правило, он состоял из языковых моделей, основанных на n-граммах, совмещенных со скрытыми марковскими моделями (HMM). С этого, как с базовой модели, мы хотели бы начать, постепенно открывая пути для комбинирования её с новыми подходами, такими как Deep Speech от Baidu. Хотя и существуют короткие статьи, объясняющие базовые основы работы фонетических моделей, не наблюдается каких-либо удобных для восприятия блогов или статей, в которых сравнивали бы возможности различных бесплатных инструментов.
Для рабочего, общего и потребительского распознавания речи, возможно, предпочтительнее приобрести Dragon или Cortana. Но, в контексте R&D, часто требуется более гибкое и целенаправленное решение. Именно поэтому мы решили составить собственный список инструментов для распознавания речи. Ниже мы перечислили лучших кандидатов из мира open source и оценили их по нескольким характеристикам.
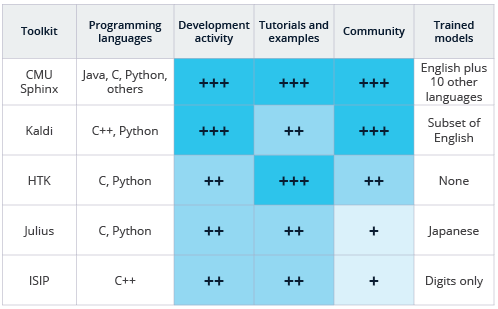
Этот анализ основан на нашем субъективном опыте и информации, доступной на веб-сайтах инструментариев и в различных хранилищах. Также это не исчерпывающий список софта для распознавания речи, большая часть которого перечислена здесь (выходящая за рамки open source). В статье 2014 года, авторства Кристиана Гайда и др., оценивается производительность CMU Sphinx, Kaldi и HTK. Следует отметить, что HTK – это не строгий open source в обычном его понимании, так как код нельзя переписывать с целью его коммерческого использования.
Языки программирования
То, насколько хорошо вы знакомы с различными языками программирования, естественным образом повлияет на предпочитаемый инструментарий. Все перечисленные варианты, кроме ISIP, имеют декораторы Python, которые или доступны на главном сайте, или их быстро можно найти в сети. Конечно, декораторы Python могут не раскрыть всего функционала кода ядра, доступного в инструментарии. Для CMU Sphinx декораторы доступны на нескольких других языках программирования.
Активность разработки
Все перечисленные здесь проекты берут своё начало из научных исследований.
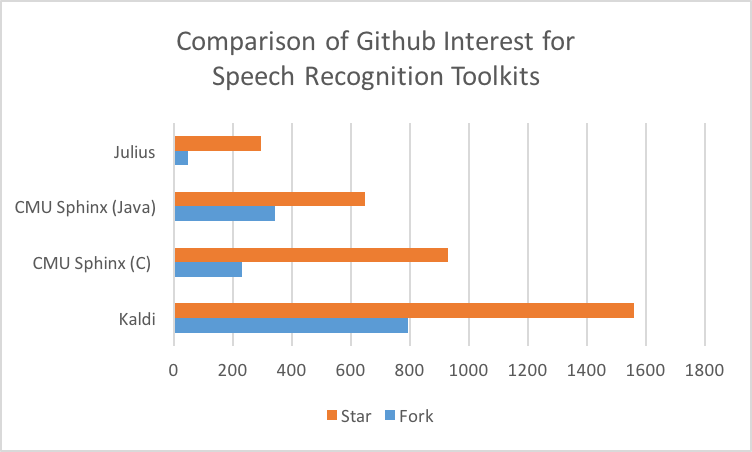
CMU Sphinx, как очевидно из названия, результат деятельности Университета Карнеги (Carnegie Mellon University). В той или иной форме он существует около 20 лет и сейчас доступен на GitHub (C и Java версии) и на SourceForge, с недавней активностью в обоих источниках. Как может показаться, у Java и у C версии всего один контрибьютор на GitHub, но это не отражает историческую реальность проекта (есть 9 администраторов и больше дюжины разработчиков в репозитории SourceForge).
Код Kaldi, который берет свои академические корни из семинара 2009 года, сейчас доступен на GitHub и насчитывает 121 контрибьютора. HTK появился в 1989 году в Кембриджском Университете, некоторое время был коммерческим, но сейчас лицензия снова принадлежит Кембриджу и HTK больше не доступен как софт open source. Хотя последнее обновление вышло в декабре 2015, предварительный релиз произошёл в 2009 году.
Julius находился в разработке с 1997 года, а его последний крупный релиз был в сентябре 2016 с некоторой активностью трёх контрьбьюторов на репозитории GitHub, что, опять же, едва ли отражает действительность.
ISIP, возникшая в штате Миссисипи, была первой новейшей open source системой распознавания речи. Разрабатывалась она, по большей части, с 1996 по 1999 год, с последним релизом в 2011. Но, перед появлением на GitHub, проект практически перестал существовать.
Сообщество
Здесь мы оценивали списки рассылки и обсуждений, а также комьюнити вовлеченных разработчиков. CMU Sphinx имеет онлайн-форумы для дискуссий и к нему проявляют активный интерес в репозиториях. Тем не менее, мы задаёмся вопросом, мешает ли дупликация репозиториев на SourceForge и GitHub более широкомасштабному вкладу в развитие проекта.
Для сравнения, у Kaldi есть списки рассылки и форумы, как и активный репозиторий на GitHub.
У HTK есть списки рассылки, но он не имеет открытого репозитория.
Ссылка на форум на сайте Julius не работает, но, возможно, на японском сайте можно получить больше информации.
ISIP, в первую очередь, направлен на достижение образовательных целей и архивы списка рассылки больше не функционируют.
Руководства и примеры
CMU Sphinx имеет очень читабельную, исчерпывающую и простую в изучении документацию.
Документация Kaldi тоже достаточно всеобъемлющая, но, по-моему, немного сложнее. Однако, Kaldi охватывает фонетический подход и подход глубокого обучения к распознаванию речи.
Если распознавание речи вам не знакомо, руководство к HTK (доступное зарегистрированным пользователям) даёт хорошее представление об этой области, в дополнение к документации по структуре и использованию системы.
Проект Julius сосредоточен на Японии, поэтому самая актуальная документация написана на японском языке, но они также активно переводят и предоставляют её на английском; здесь можно найти несколько примеров работающего распознавания речи.
И наконец, проект ISIP имеет некоторую документацию, но в ней слегка сложно ориентироваться.
Готовые модели
Хотя основной причиной использовать эти open source или бесплатные инструменты является желание создавать специализированные модели распознавания голоса, большим преимуществом является возможность общаться с системой из коробки.
CMU Sphinx включает в себя английский и много других моделей, готовых к использованию, с документацией для подключения их к Python, входящих в состав readme GitHub.
Инструкции Kaldi для декодирования с помощью существующих моделей спрятаны глубоко в документации, но мы, в итоге, обнаружили в субдиректории репозитория egs/voxforge модель, обученную на, в какой-то мере, английском наборе данных VoxForge. Распознавание можно осуществить, запустив скрипт в online-data субдиректории.
В других трёх пакетах мы не разбирались так углублённо, но все они идут в комплекте с, как минимум, простыми моделями или оказываются совместимы с форматом, представленным на сайте VoxForge, активном краудсорсинговом репозитории данных по распознаванию речи и готовых моделей.